


DeepSeek and Privacy concerns
#172 - Is DeepSeek really a privacy nightmare that sends data to China🇨🇳 , or is it the US 🇺🇸 big tech running scared?
If you are not sure of what is happening with DeepSeek, don’t worry, here is a primer:
What exactly are we talking about here?
We are talking about the Chinese AI company - DeepSeek.
DeepSeek made waves by releasing an AI model that beats OpenAI’s most celebrated model o1. DeepSeek’s R1 model beats OpenAI’s o1 model in most standard tests.

The ‘making waves’ 🌊 part, however is not because of superior performance 📈 of the model. It was because of the cost of the model.

That’s 3% of the cost of OpenAI. The combination is what is creating the tsunami. Better performance 📈 and much much lower costs 📉.
How does DeepSeek do it?
If you go through their paper on Github, you will see an interesting deviation from the ordinary. They use large-scale reinforcement learning without supervised fine-tuning. Let’s break it down.
Reinforcement learning is unsupervised learning where there are rewards for correct reasoning and punishments for incorrect reasoning. This is generally preceded by the supervised learning phase, where labeled data is provided. DeepSeek skipped step 1 and went to step 2. It was faster and cheaper, but they had issues. So they moved to multi stage learning - meaning learning from little chunks of the data and using that learning to improve. Also, they used a little bit of data known as ‘cold start data’ that essentially means a small sample to use as a base to start the learning process - the sourdough starter if you will.
The paper is more technical and interesting. Download the pdf here.
That’s good right? So what’s the problem?
The problem is this. More than $1 trillion has been wiped out from the stock market for the big tech firms. They fear that their billions of dollars of funding will dry up because a $6 million startup beat OpenAI in the model race.
Some people raised concerns about privacy of data when using DeepSeek.
This gentleman even called DeepSeek a trojan horse in a much commented LinkedIn post. Using words like “suspiciously cheap” and “backdoors everywhere”, he says that DeepSeek is a threat. This sentiment is probably echoed by many people who find it difficult to believe the origin, price and behavior of DeepSeek models.
DeepSeek quickly became the most downloaded app on the Apple App Store, replacing, well, ChatGPT. Then it faced massive cyber attacks.

Privacy concerns
Gen AI needs shiploads of data to learn. This is usually obtained from all sort of sources, legal and illegal. Meta used pirated books sites to train their Llama models.

The fact that DeepSeek is Chinese, means that it stores data in 🇨🇳 China. This leads to the fear that the Chinese government can have access to the data at will. Many tech sites have covered this fear quite prominently.
Given the privacy concerns, I asked ChatGPT to compare the privacy policies of DeepSeek and OpenAI. This is what it said:

Not much of a difference, eh?
What’s more important is that data is collected only when you use the API or the web portal of DeepSeek. Most implementations of DeepSeek are using local models downloaded on local machines that do not send any data out.
The same Wired piece that says:

also says this in the article body.

So, downloading the models and running them locally sends no data. Also the model is fully open source:

Worth exploring safely, right?
So, how do I setup DeepSeek locally?
Well, it’s quite easy. First, you need a reasonably powerful laptop with a strong GPU. Then you need Ollama and you can get the model on your console. If you want a GUI on the browser, you can use something like streamlit to get it going. Here is the code for the same:
import streamlit as st
import ollama
def main():
st.set_page_config(page_title="Ollama Chat", layout="wide")
st.title("Chat with Ollama Model")
# Select model
model = st.selectbox("Choose Ollama model:", ["llama3.1:latest", "deepseek-r1:latest"])
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat history
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# User input
user_input = st.chat_input("Type your message")
if user_input:
st.session_state.messages.append({"role": "user", "content": user_input})
with st.chat_message("user"):
st.markdown(user_input)
# Generate response and stream it
with st.chat_message("assistant"):
response_container = st.empty()
bot_response = ""
for chunk in ollama.chat(model=model, messages=st.session_state.messages, stream=True):
bot_response += chunk["message"]["content"]
response_container.markdown(bot_response)
st.session_state.messages.append({"role": "assistant", "content": bot_response})
if __name__ == "__main__":
main()This works perfectly on my Mac and lets me chat with the DeepSeek model that I have pulled from Ollama.
For this to run, you have to install Ollama, pull the DeepSeek model and run it. Then you have to ensure that you have ollama and streamlit libraries installed. After that, it is essentially smooth sailing. Your output looks something like this:
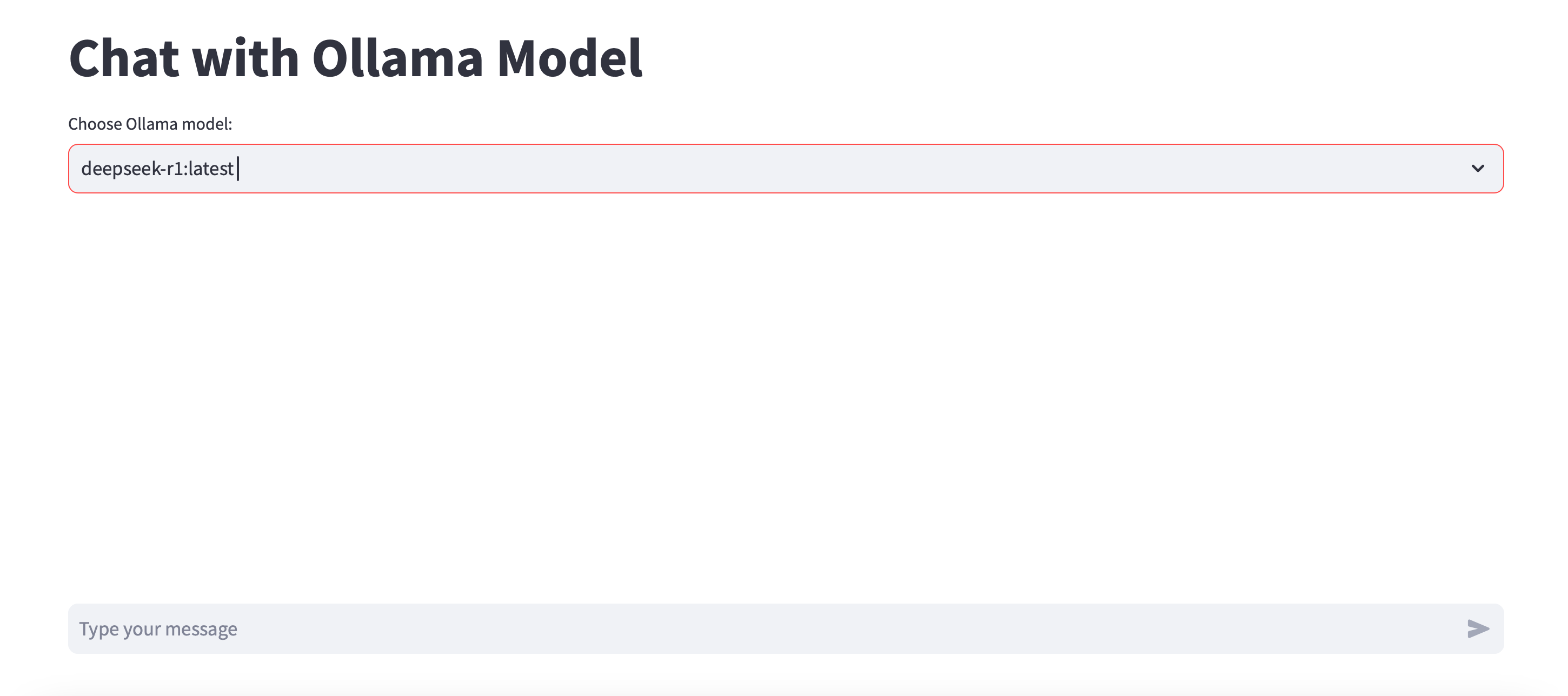
Depending on the model that you have pulled, you will get responses. I have the very basic 4.7Gb model on my machine. It does reasonably well with some of the basic questions:

After some thinking (the thinking process is clearly visible), this is what DeepSeek answered:

Take Action?
A technology advancement like DeepSeek R1 deserves to be explored safely. This could really be the change in direction of AI. Explore the model safely and decide if it is worth using in your processes and applications.