
The Data Dilemma: AI Giants Leverage Social Media to Train Their Algorithms as the world runs out of data
CyberInsights LongReads#6: AI companies turn to vast pools of social media data to train their models. What about privacy, consent, and ethics?
The world is running out of data. Yes, you heard that right. The world is running out of data to train AI models. Scientists predict that we will run out of data by 2030. No wonder AI model creators are hosing up all possible data, from everywhere, especially your social media posts.
I started exploring this topic after LinkedIn surreptitiously started using our data to train AI models. I have put up a quick post on how to disable this.

The bigger question, however, remained. Which other social media platforms use my data to train their AI models? What consent have I provided to them?
So, I started with the obvious. Asking AI to identify the list of social media platforms that use my data to train their AI model. Here is the list:
Almost all the major social media platforms use published (and sometimes unpublished) data to train their AI models.
What data is used and how?
LinkedIn
I started with LinkedIn, because that is the only social media platform that I use. (I have an account on X, but don’t tweet actively.) A deep dive into LinkedIn’s privacy policy reveals this:
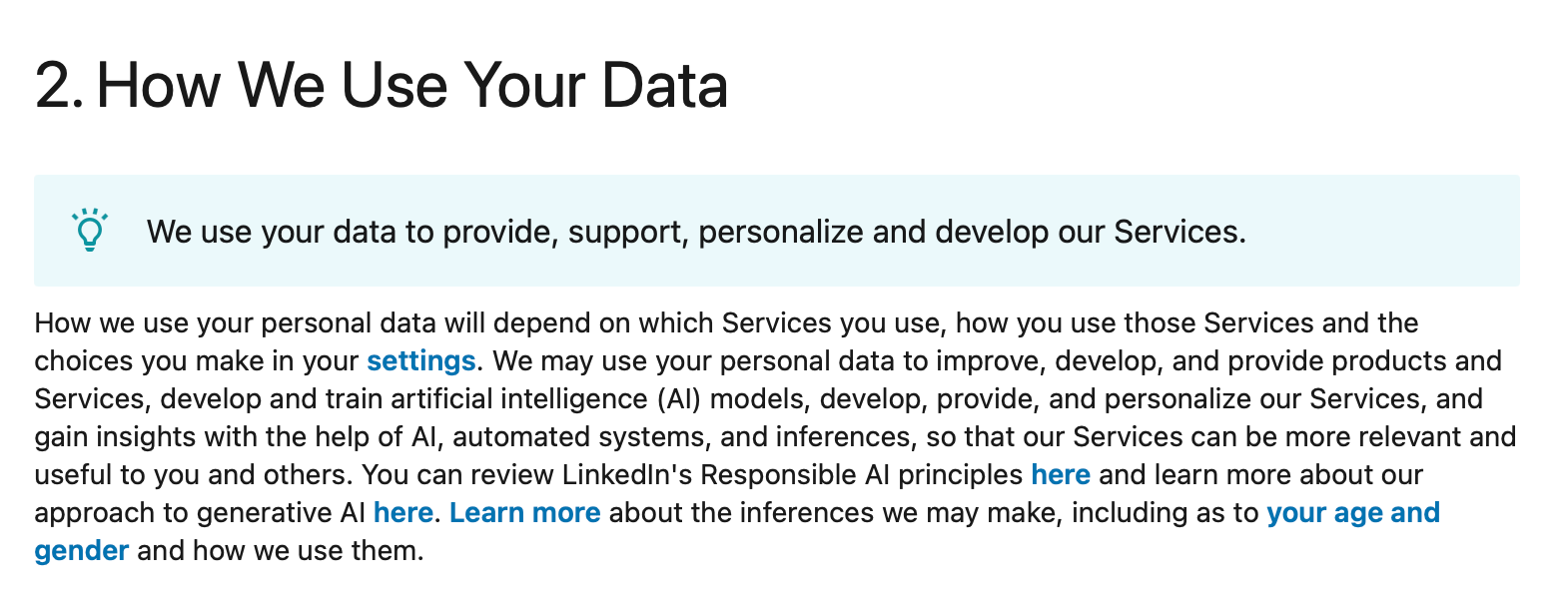
It clearly states that LinkedIn uses personal data to train AI models.
But, what data?? Almost everything you do on the platform.
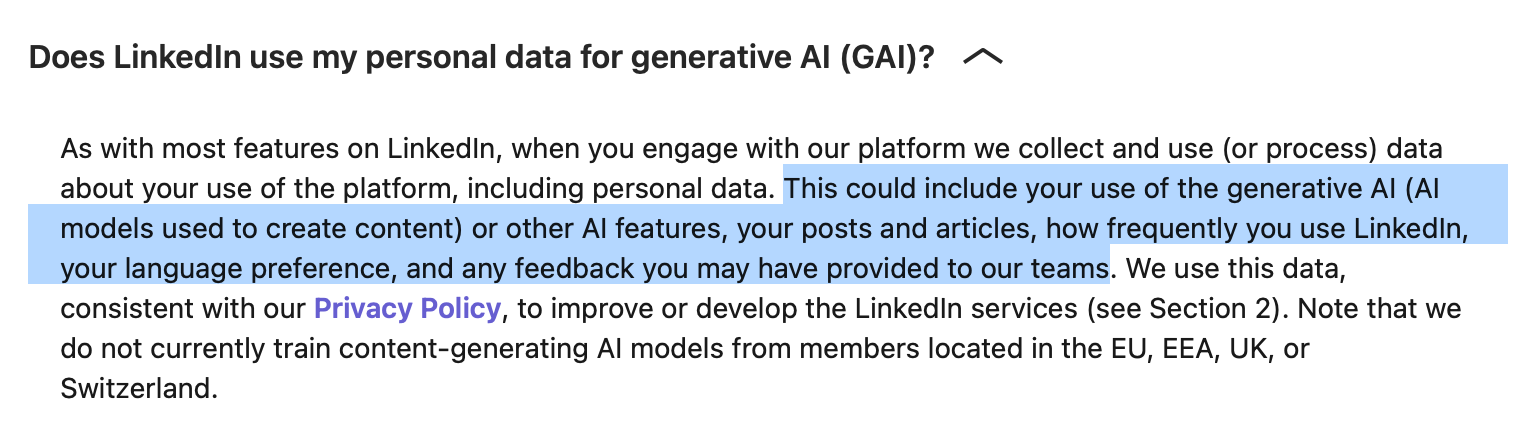
The hogwash that is LinkedIn’s Responsible AI principles
LinkedIn says that it’s core principles of AI are:

Well, read the second principle - Upholding Trust by committing to privacy. How would you do that if you enable data usage for AI by default?
Microsoft (the owner of LinkedIn) is proving that it’s ‘Responsible AI’ practice is just lip service.
Moving on to the other biggie, Google.
YouTube
Google’s flagship AI model is Gemini. The latest being the 1.5 model. Google is tight lipped about the data it uses for training its AI models. However, given that Google owns some of the most important assets on the internet, our assumption that all the data is used for training the AI model. This assumption cannot be too far off the mark.
Google talks about YouTube’s approach to Gen AI, but does not say what date it uses to train its models.

However, the privacy policy of YouTube has mentioned certain specific purposes for using your personal data like ‘service improvement’ & ‘research and development’. Both can be interpreted as “We can use your data to train our AI models so that we can provide you an improved service.”
Google is very secretive about the data it uses to train its models.
Meta - Facebook, Instagram & WhatsApp
The company every cybersecurity professional loves to hate.
Facebook has an open source model Llama3 - one of the most popular and capable models for Gen AI. What data is used to train it?
Among other data, Facebook and Instagram data is used for training Llama3. In fact, Mark Zuckerberg even said that it is not a competitive advantage as the data is indexed by search engines and Google is probably using it anyway. That makes it fair game.
It gets stickier when it comes to WhatsApp, though.
Meta has incorporated MetaAI into WhatsApp. When you chat with Meta AI, the data is used for training its AI model.
My concern is that having Meta AI and Search in same data field might lead to users inadvertently using AI when wanting to use search. When you start typing, this is what you get:
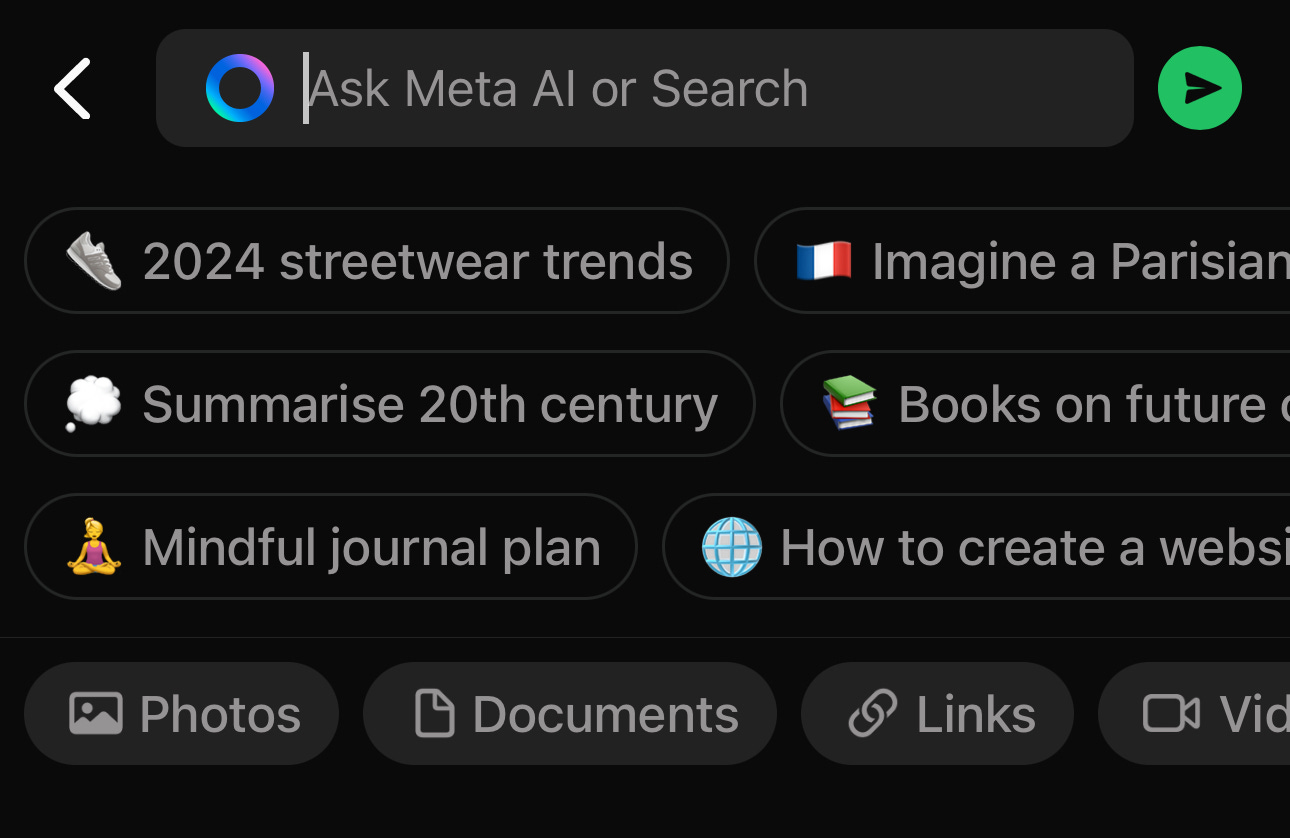
Meta encourages you to interact with its AI and you have to be really careful to search WhatsApp content and not get inadvertently sucked into AI training.
End to End Encryption when one end has AI slurping up data.
How does end to end encryption work when the end where the encryption happens has Meta AI that can, potentially, access all your chats and messages before they get encrypted.
I don’t know if Meta AI has access to the data before being encrypted. That’s a big red flag and I hope that Meta clarifies this.
TikTok
TikTok is not exactly known for its privacy first approach. Anything you do on the platform is available to TikTok to analyse, slice and dice and train any AI models that it wants. Even your unpublished content.
“When you create User Content, we may upload or import it to the Platform before you save or post the User Content (also known as pre-uploading), for example, in order to recommend audio options, generate captions, and provide other personalized recommendations. If you apply an effect to your User Content, we may collect a version of your User Content that does not include the effect.”
This is what they say about your unpublished data.
All this data can, of course, be used to train AI models. TikTok is not very shy about mentioning it in their privacy policy. There is a specific bullet in their ‘How We Use Your Information” section of their privacy policy.
To train and improve our technology, such as our machine learning models and algorithms.
SnapChat
SnapChat has a ‘My AI’ chatbot. If you chat with it, that is used to train the AI model. Private messages are not used. However, SnapChat is not very clear what it does with the Metadata.

SnapChat, by far seems to be the most simple and easy to understand privacy policy and disclosure of what they do with AI and the data used for AI:
X (I still like calling it Twitter)
X uses your data to train it’s AI - Grok.

Your messages, chats and posts are used to train Grok. This functionality is enabled by default and you have to go to settings and disable them. Just like Microsoft and LinkedIn.
What about data deletion, then?
A tenet of data privacy laws across the world is the ability for a user to ask for data deletion. Article 17 of the GDPR and laws in about 13 US states explicitly allow the user to ask for data deletion. India’s DPDP act also has a similar clause.
How do AI models plan to do this?
It’s not very clear. Once the data is embedded into a vector database and the system is trained on it, it becomes very difficult to extricate a specific data item and delete it.
You have to retrain the model, or do an approximate deletion, but you cannot really be sure if that is possible. Retraining is expensive and requires a lot of GPUs.
This is a complex topic and requires a bit of understanding of how models are trained and how the vector embeddings are stored. Let me know if you want me to do a separate piece on deleting personal data from AI models.
That’s a wrap on the deep dive of Data Privacy and AI model training.